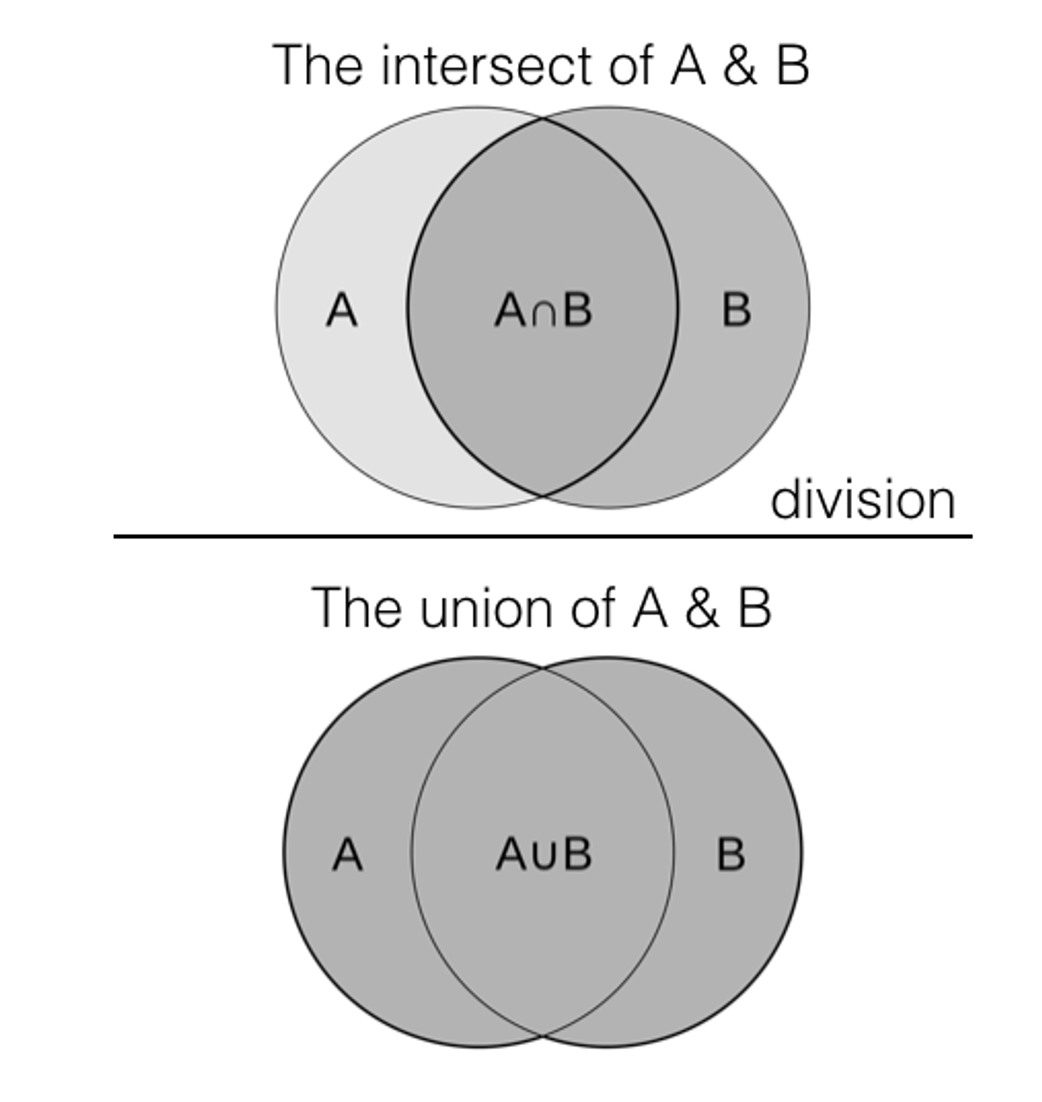
Jaccard Similarity Measure.
Jaccard Similarity Measure.

Manual test data creation using SELECTs and UNION ALL

iPadMini has whitespaces removed

MacbookPro has whitespaces removed

Convert all to lowercase.

Convert all to lowercase.

Non-overlapping tokens are created.

Getting all possible bigram sequences with overlapping tokens.

Using lambda functions to extract overlapping bigrams.

Extracting an overlapping trigram.

Extracting overlapping 4-grams

5-grams gives us 4-grams as well

5-grams without 4-grams.

7-grams

Summing partial sums in a loop.

The only unique element in featurevector2.

Mateialized view of featurevector1 after it has been tokenized.

Mateialized view of featurevector2 after it has been tokenized.
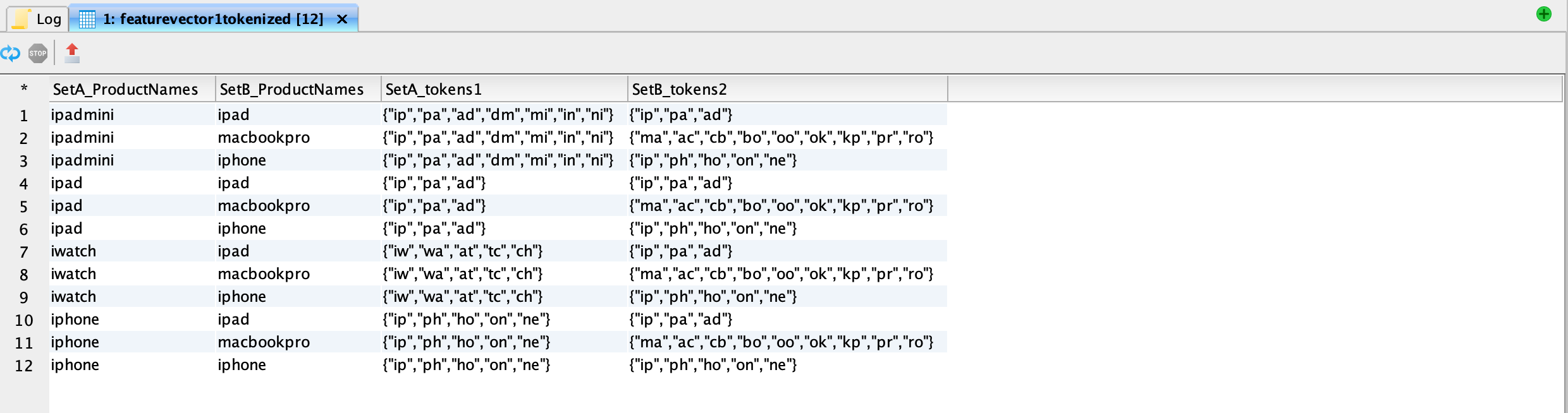
Cross join with the tokens
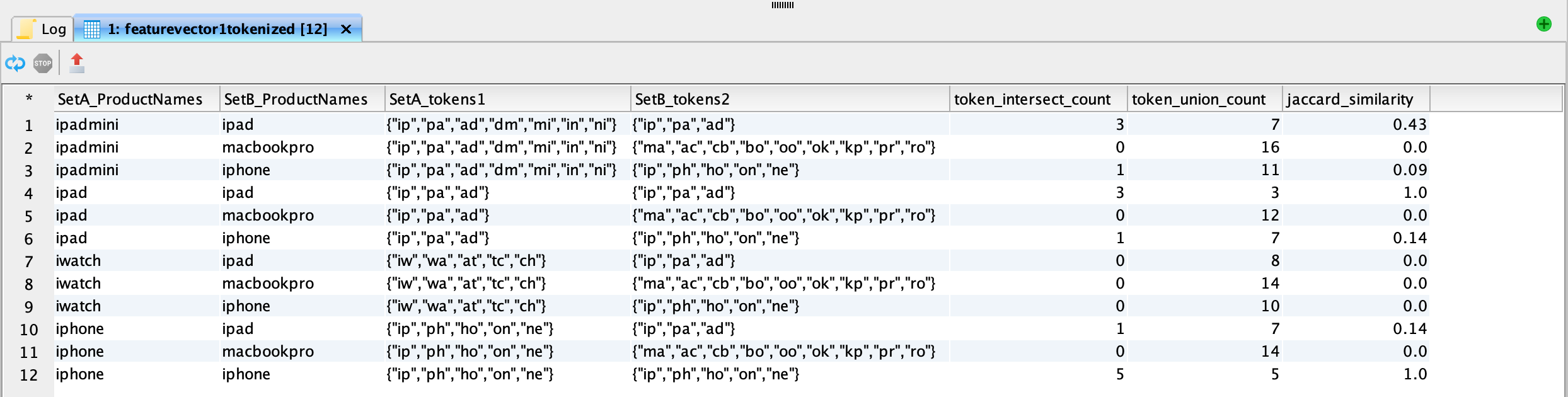
Jacard Similarity Measure across two feature vectors

Similarity join between featurevector1 and featurevector2.