

Scrolling to right, you will see identityMap field and then the segmentMembership.
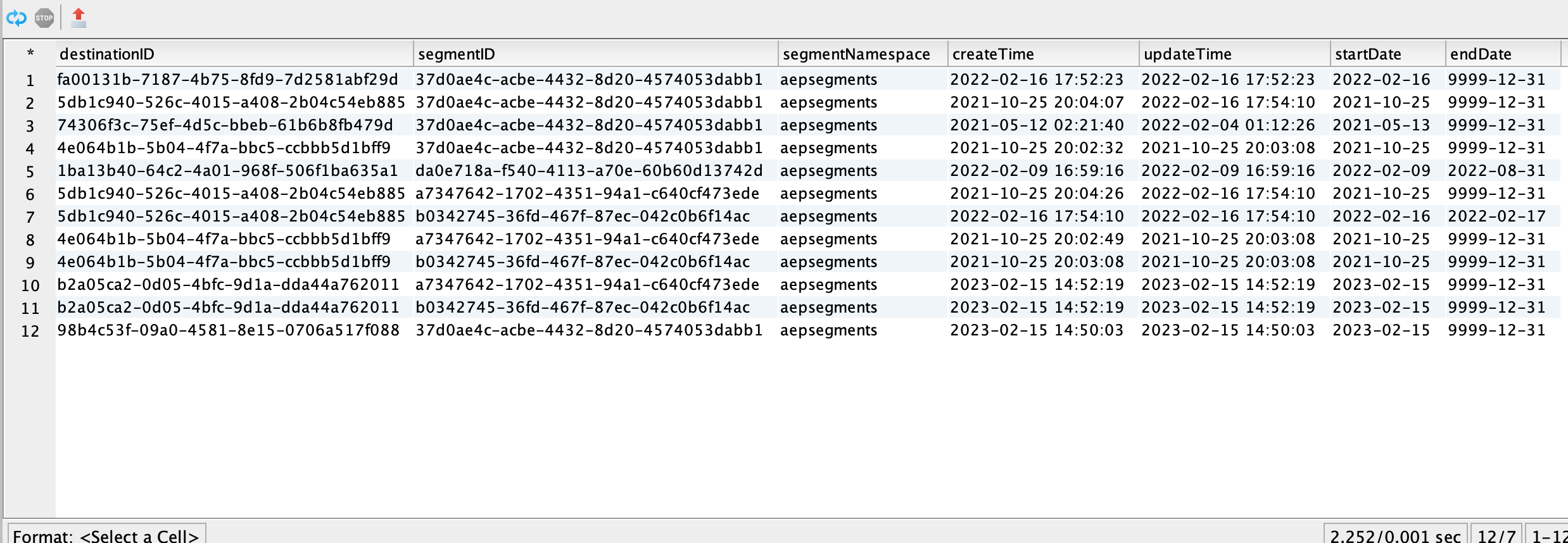
Destination to segment napping

Segment ID to segment mapping raw table.
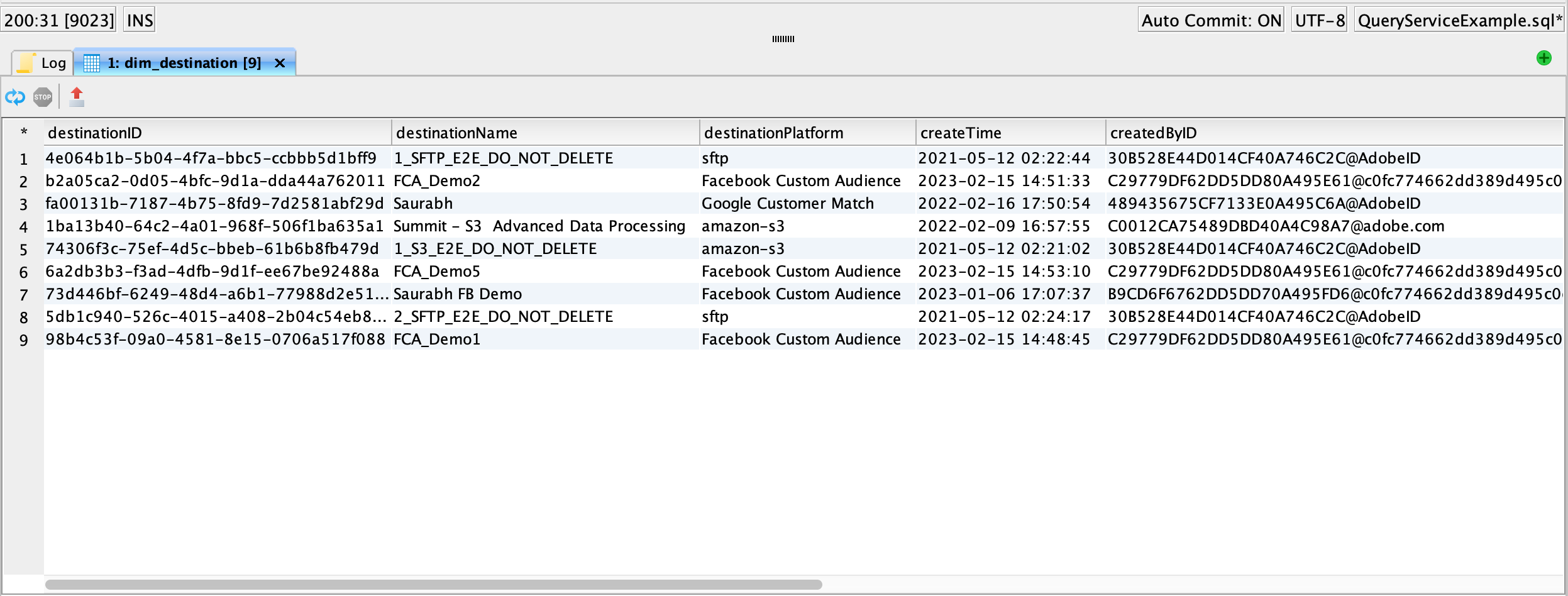
Destination ID to Destination Account Name mapping

Source identity namespaces that could map to the destination identity namespace.

Deestination identity fields being used in my environment.


Copy the dataset_id from the query result

Query result

Dataset name is available for dataset id typed into Univeersal search


Query result

Query result

Query result

Query result

Profiles Overview page has merge policy filter that gives you the same count.

Query result
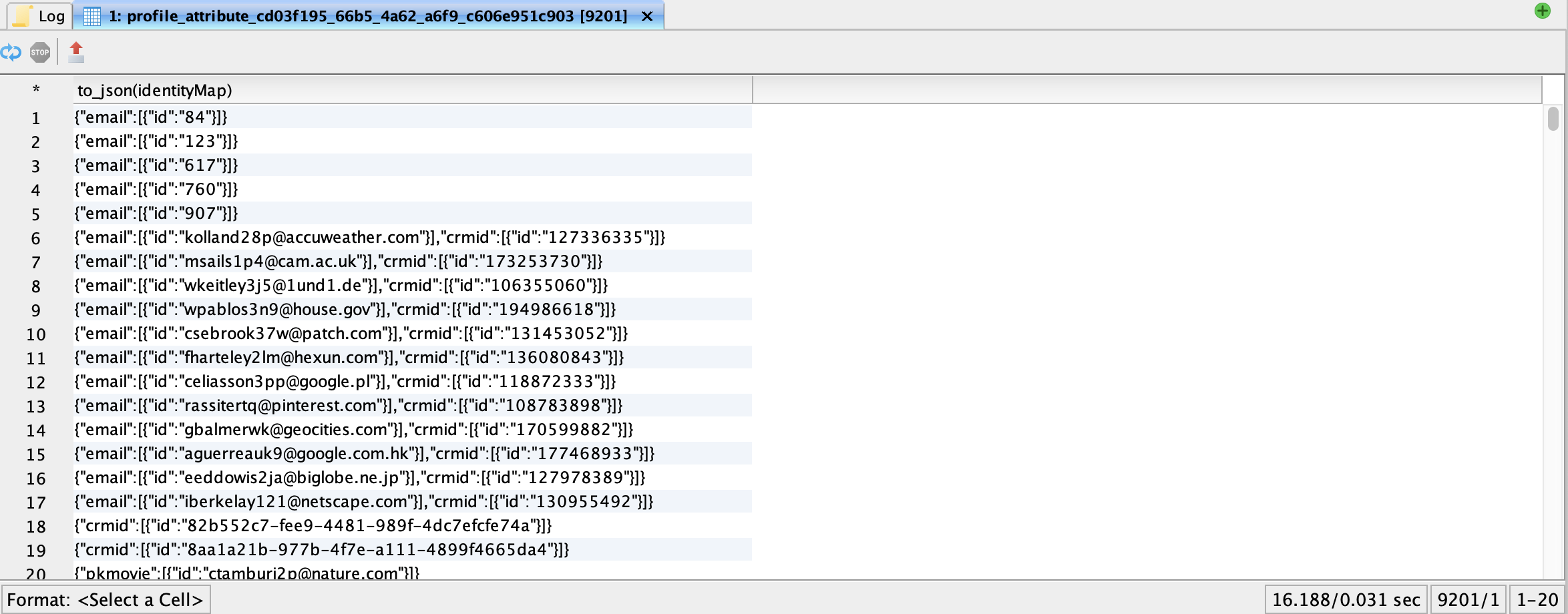
Identity maps structure

Array of identity values

Exploding the array helps you extract the identities.

explode_outer retains the nulls for the identity namespaces

Generate the unique ID without llosing identity associations.
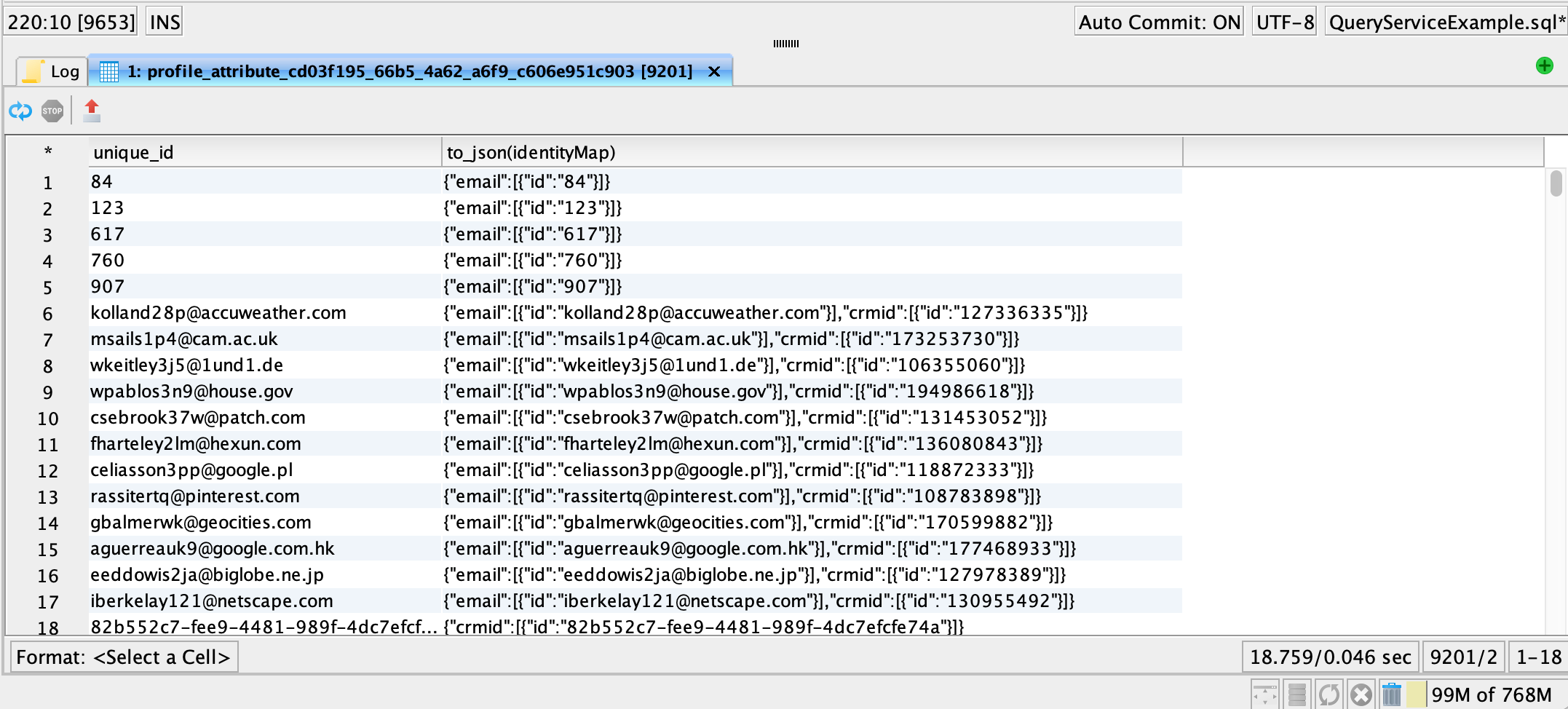
COALESCE function retrieves the first non-zero value in a list and is a good choice for a unique ID for the profile in our example.

email identities have been separated into separate rows without breaking profile association.
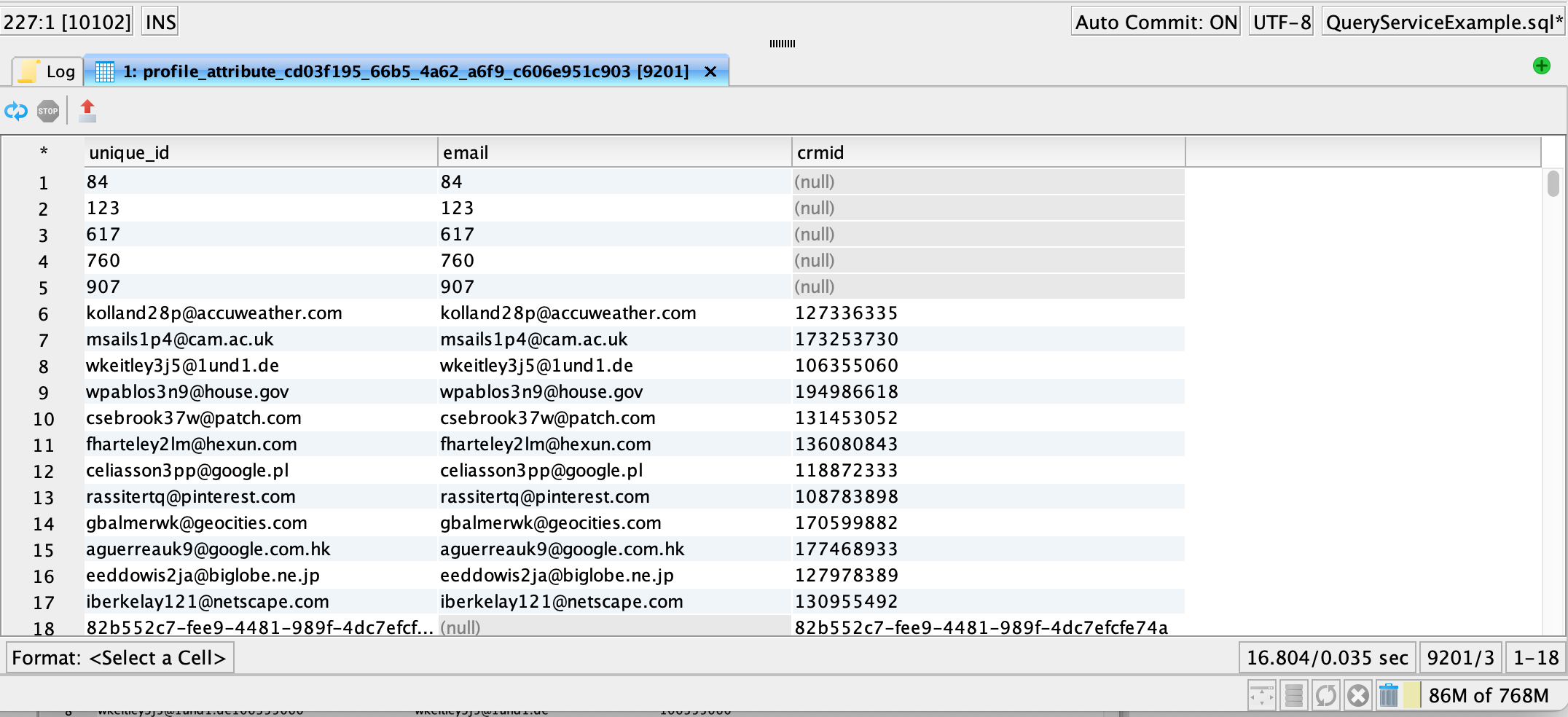
Identity lookup table in relational form
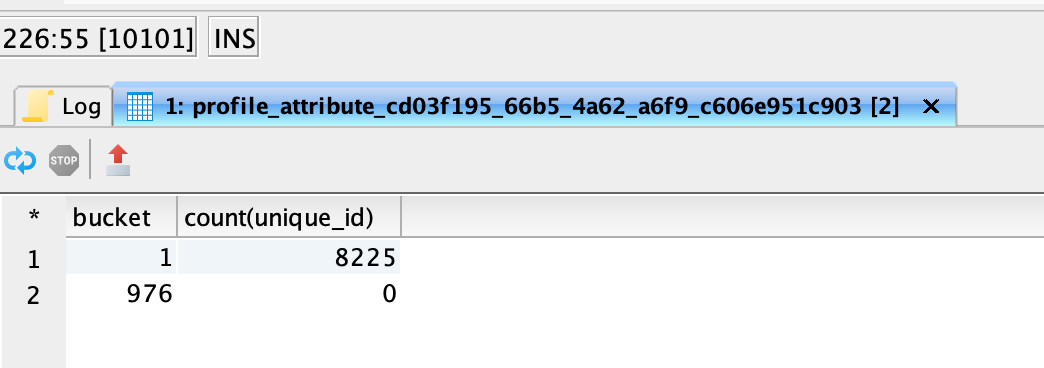

Query result

Query result
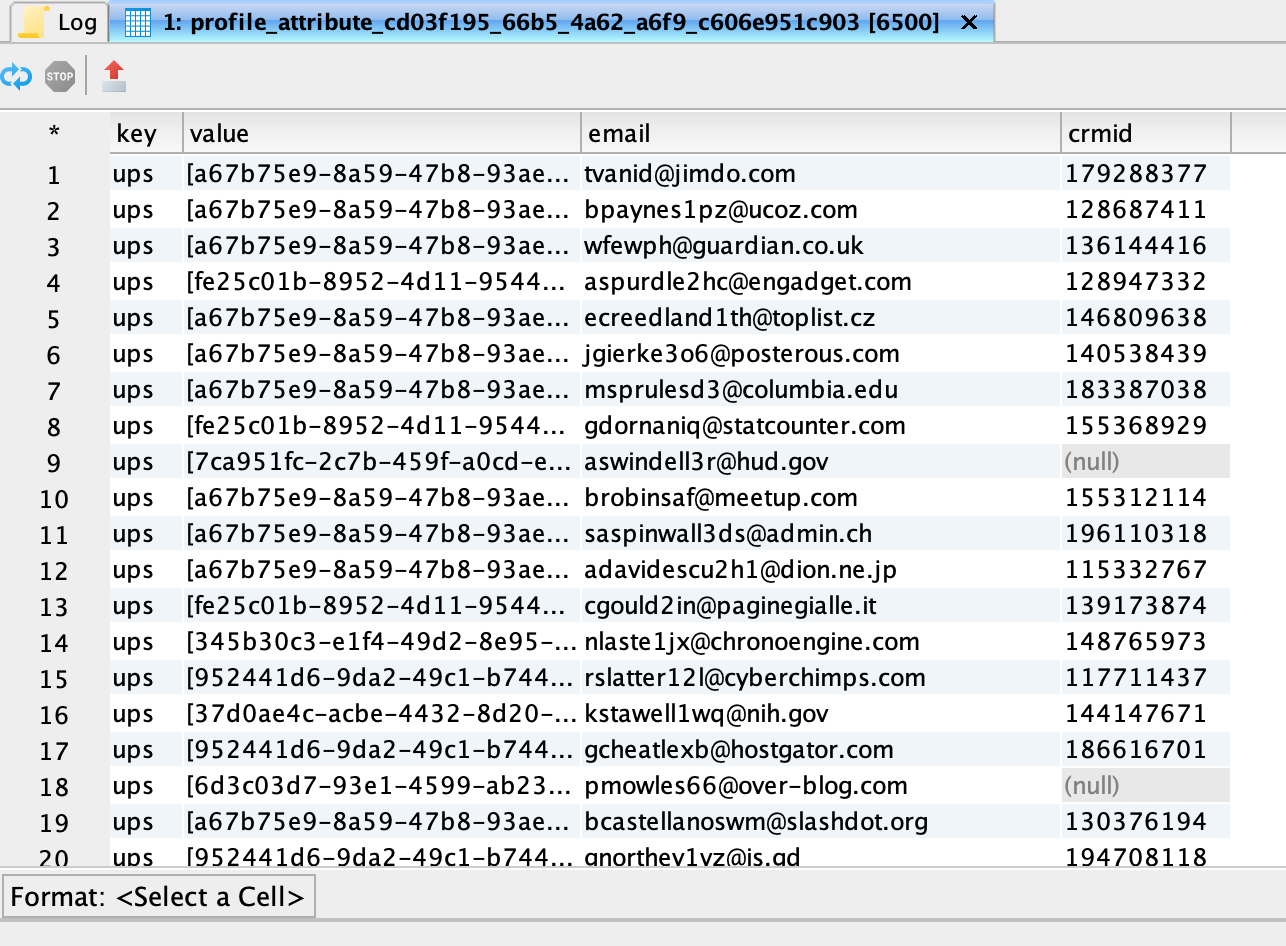
Query result

Query result.

Query result

Query result

Query result

Query result
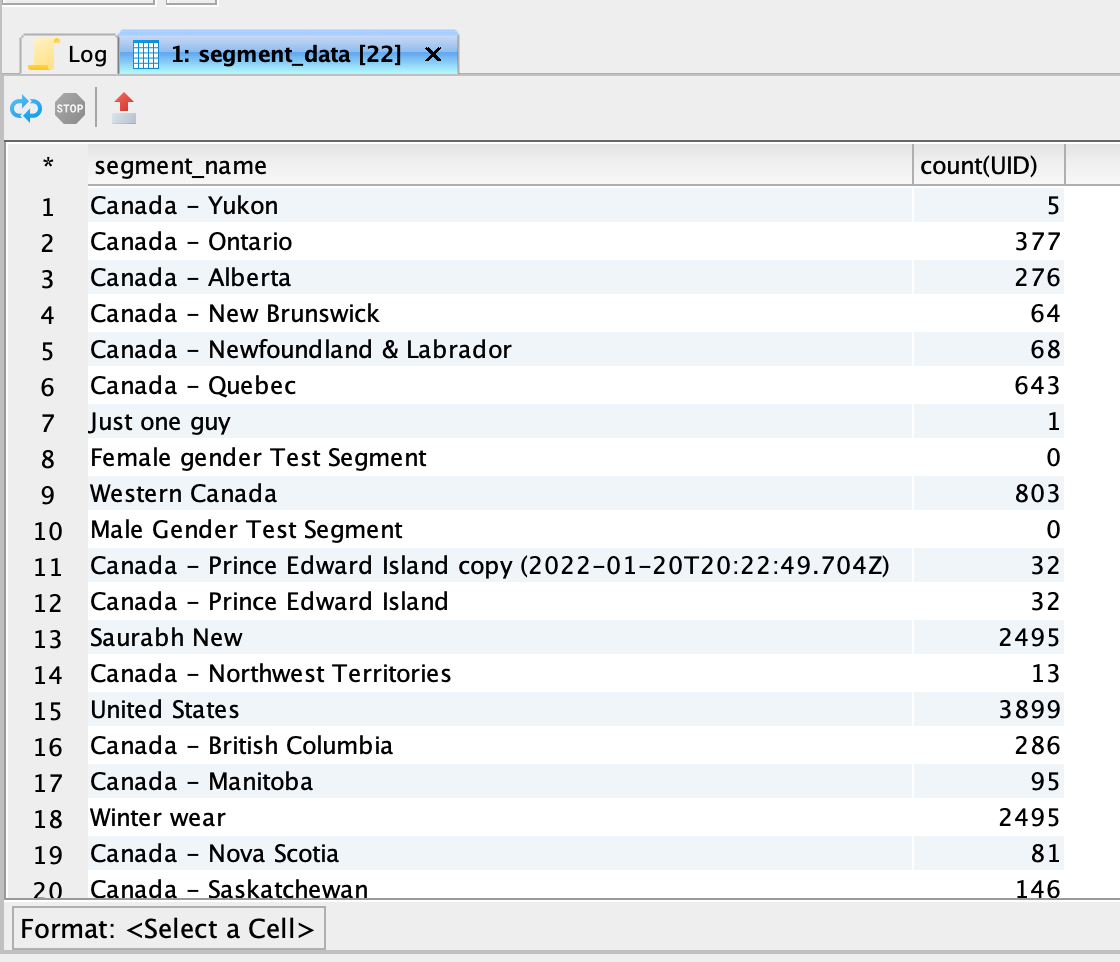
Query result

Query result

Query result


Query result

Query result

Query result

Query result

Query result
Query result

Query Result

Query Result

Query result.