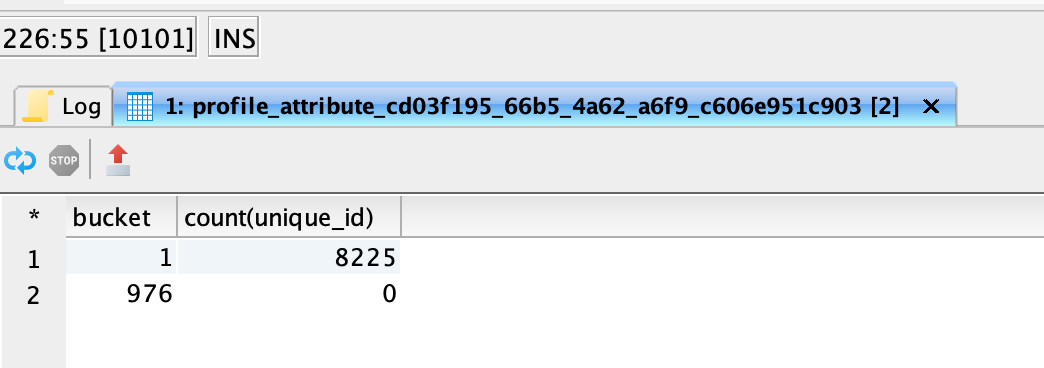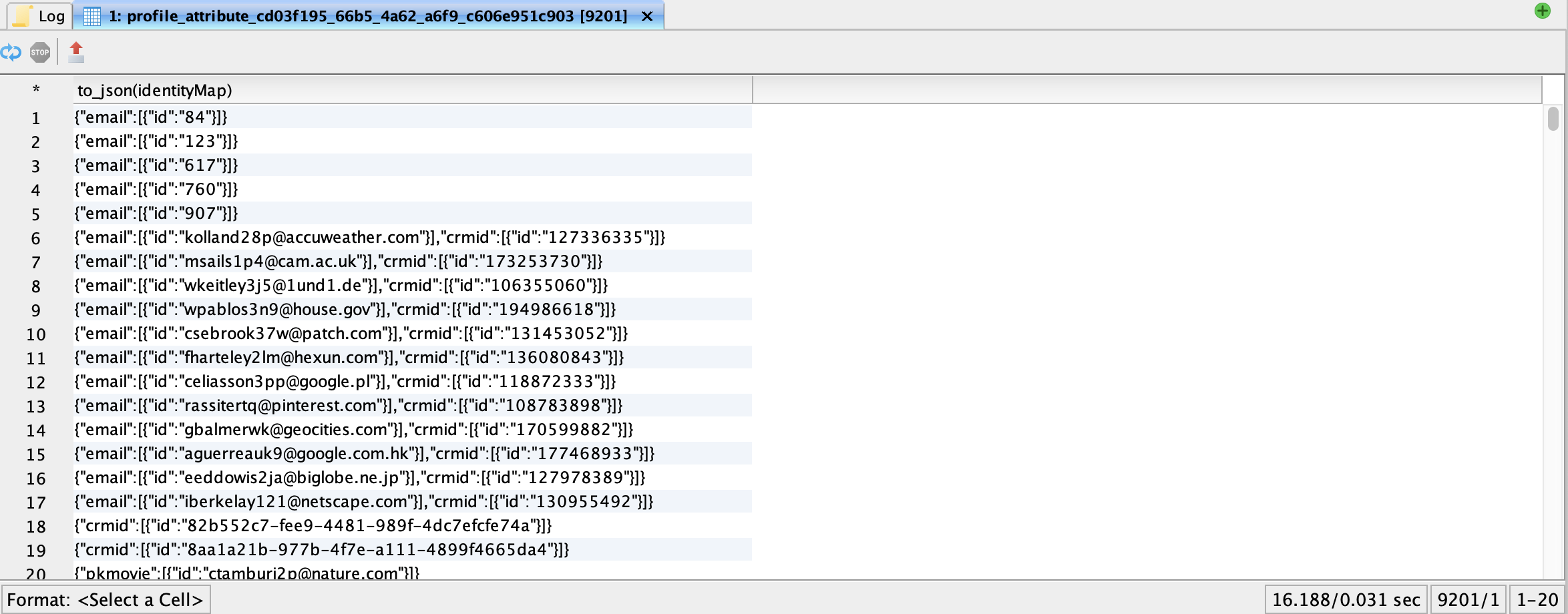
Identity maps structure

Array of identity values

Exploding the array helps you extract the identities.

explode_outer retains the nulls for the identity namespaces

Generate the unique ID without llosing identity associations.
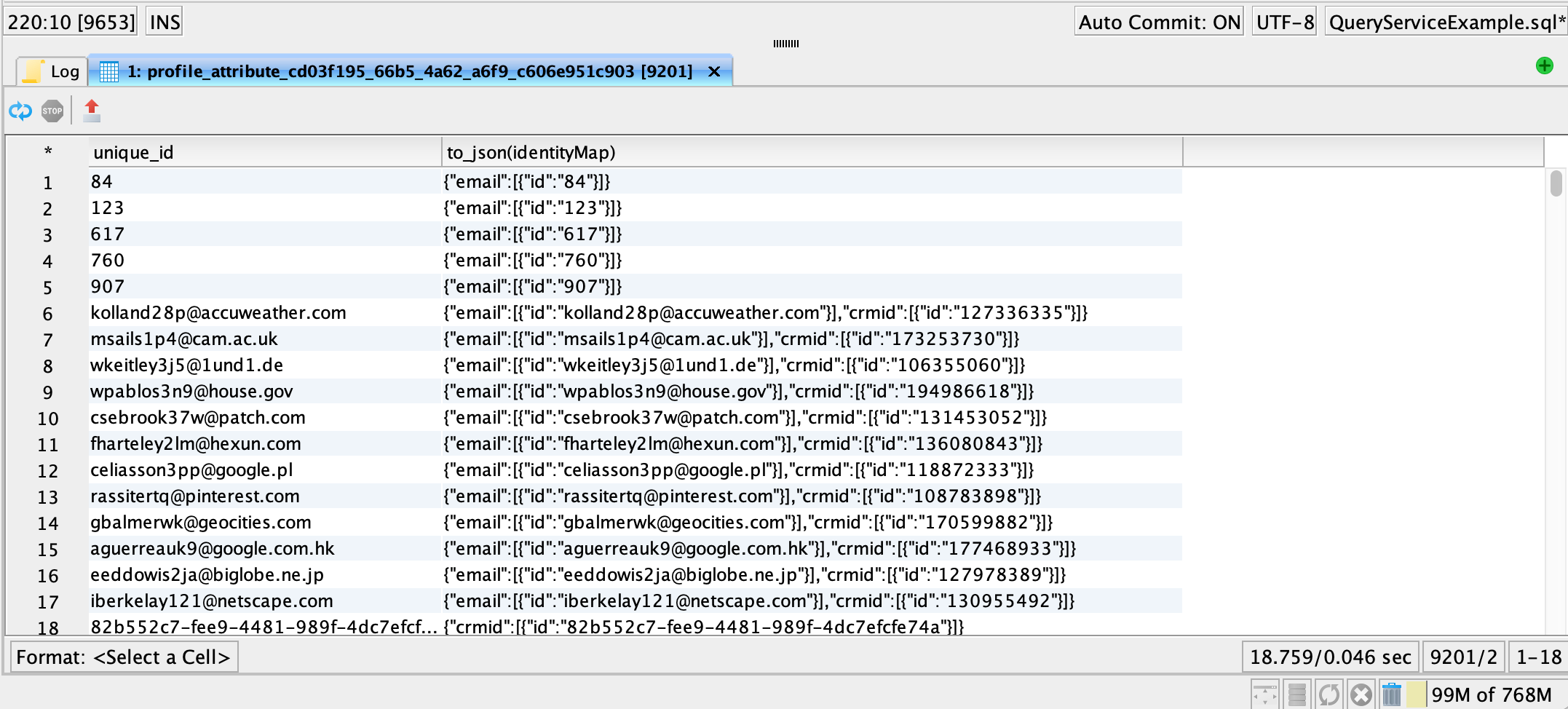
COALESCE function retrieves the first non-zero value in a list and is a good choice for a unique ID for the profile in our example.

email identities have been separated into separate rows without breaking profile association.
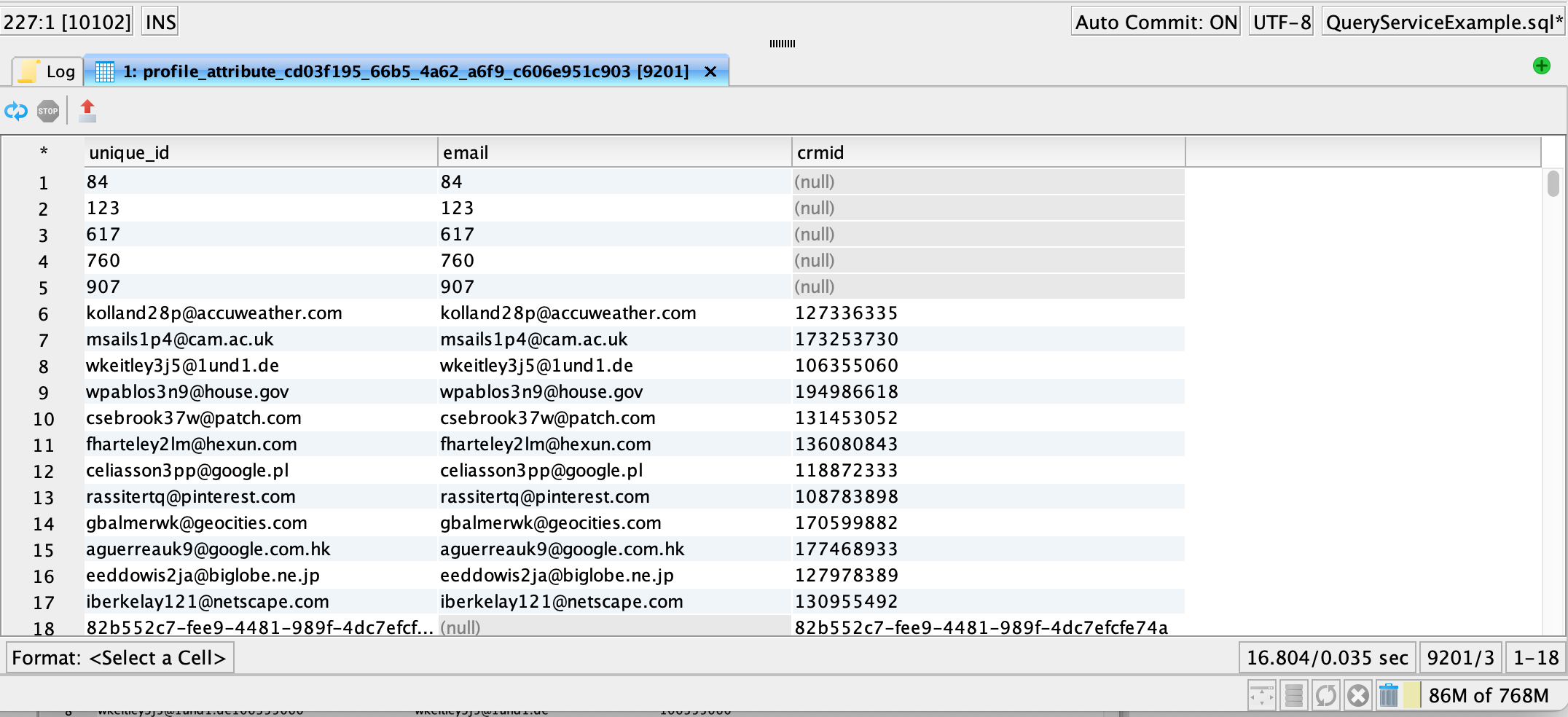
Identity lookup table in relational form